This page provides examples for using Python code steps. Every example depends on specific input_data, which is provided under the "Input Data" field when setting up your code step.
For example, if you add these three input data fields:
bodynamesubject
You can reference them in your code as input_data['body'], input_data['name'], and input_data['subject']. Make sure you review the code examples and provide the right inputs, otherwise nothing will work as expected.
Python is an advanced programming language. If you're not familiar with Python, ask a developer for help.
Introductory examples
Each of the four examples below expects a name in the "Input Data" field.
Here's an easy example:
return {'id': 1234, 'hello': 'world!', 'name': input_data['name']}
You can also bind the result to output—the code above has exactly the same behavior as the code below:
output = {'id': 1234, 'hello': 'world!', 'name': input_data['name']}
Here's an example with an early empty return:
if input_data['name'] == 'Larry':
return [] # skip this input
return {'id': 1234, 'hello': 'world!', 'name': input_data['name']}
Introductory HTTP example
A more complex example (no "Input Data" needed):
response = requests.get('http://example.com/')
response.raise_for_status()
return {'id': 1234, 'rawHTML': response.text}
Introductory logging example
This example expects a name in the "Input Data" field:
if input_data.get('name'):
print('got name!', input_data['name'])
return {'id': 1234, 'hello': 'world!', 'name': input_data['name']}
Test your action and check the data to find the print result.
Simple math: divide by two
This example expects a rawNumber in the "Input Data" field:
return {'id': 1234, 'hello': 'world!', 'name': input_data['name']}
0
Simple email extraction
This example expects a rawText in the "Input Data" field:
import re
emails = re.findall(r'[\w._-]+@[\w._-]+\.[\w._-]+', input_data['rawText'])
return {
'firstEmail': emails[0] if emails else None
}
Complex multiple email extraction
This example expects a rawText in the "Input Data" field:
import re
emails = re.findall(r'[\w._-]+@[\w._-]+\.[\w._-]+', input_data['rawText'])
return [
{'email': email} for email in emails
]
This will trigger multiple downstream actions, one for each email found. If no emails are found, nothing happens.
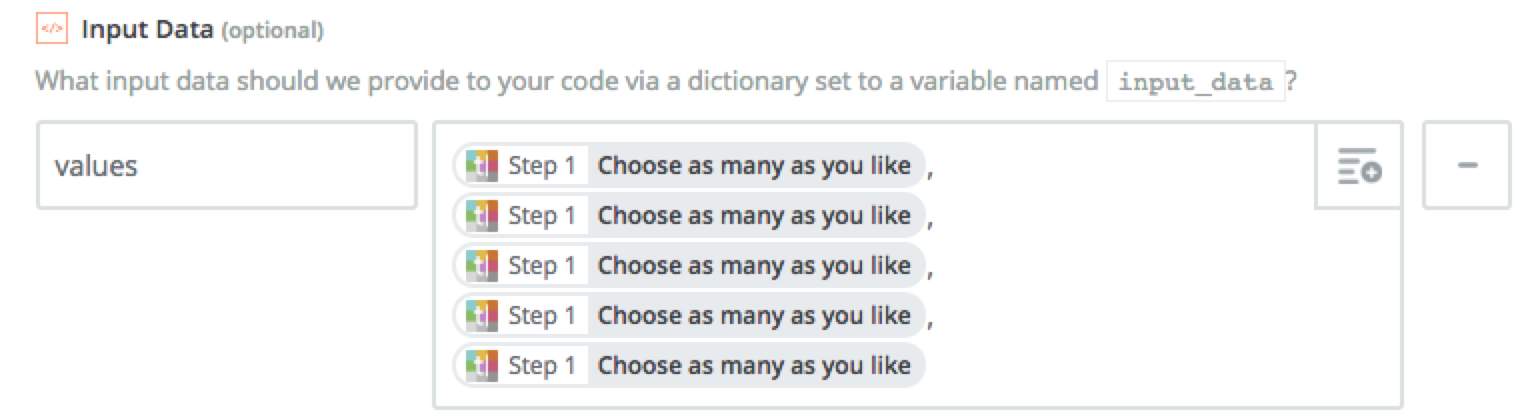
Formatting a comma-separated list
If you need to create a comma-separated list and eliminate blank values, this snippet will create the list and remove blanks. This example expects a values entry in the "Input Data" field like this:
import re
values = re.sub('(^,+|,+$)', '', input_data['values'])
values = re.sub(',+', ',', values)
return [{'values': values}]
Weather JSON API call
This example expects a zipCode in the "Input Data" field:
zc = input_data['zipCode']
url = 'http://api.openweathermap.org/data/2.5/weather?zip=' + zc + ',us'
response = requests.get(url)
response.raise_for_status()
return response.json()
XML parsing
If you need to parse XML and return it, you can use the built-in XML libraries:
from xml.etree import ElementTree
root = ElementTree.fromstring('''
1
2
3
''')
return [
{field.tag: field.text for field in child}
for child in root.findall('child')
]
If you need to make an API call to parse XML, you can combine this with the requests examples above:
from xml.etree import ElementTree
response = requests.get('http://yourapi.com/xml')
root = ElementTree.fromstring(response.text)
return [
{field.tag: field.text for field in child}
for child in root.findall('child')
]
The part for iterating the data (for child in root.findall('child')) will change depending on the API response. It will not be exactly parent or child like the example above.
Store state
Use the StoreClient utility to store data between runs. For example, this counter tracks how many times it is run:
store = StoreClient('some secret')
count = store.get('some counter') or 0
count += 1
store.set('some counter', count)
return {'the count': count}
Learn more about StoreClient.
Generate unique ID (UUID)
When you use a Code trigger to connect to an app that uses polling to retrieve new data, your Zap will only trigger if the ID is unique. This prevents duplicates.
In the 'hello': 'world!' example above, the Zap will trigger the first time it receives 'id': 1234. If a later poll retrieves 'id': 1234 again, it will not trigger for that data.
One way to make the ID unique each time the Zap runs is to use the uuid library:
import uuid
return {
'unique_id': str(uuid.uuid4())
}
Only once per hour
In conjunction with a Filter step, you can use code like this to limit the number of times your Zap can run per hour (which is configurable):
every_seconds = 60 * 60
store = StoreClient('some secret')
import time
now = int(time.time())
last_post = store.get('last_post') or now - every_seconds + 1
output = {'run': 'no'}
if last_post < (now - every_seconds):
output = {'run': 'yes'}
store.set('last_post', now)
# set up a filter after this that checks if run is exactly yes
Without a follow-up Filter step, this will not work.
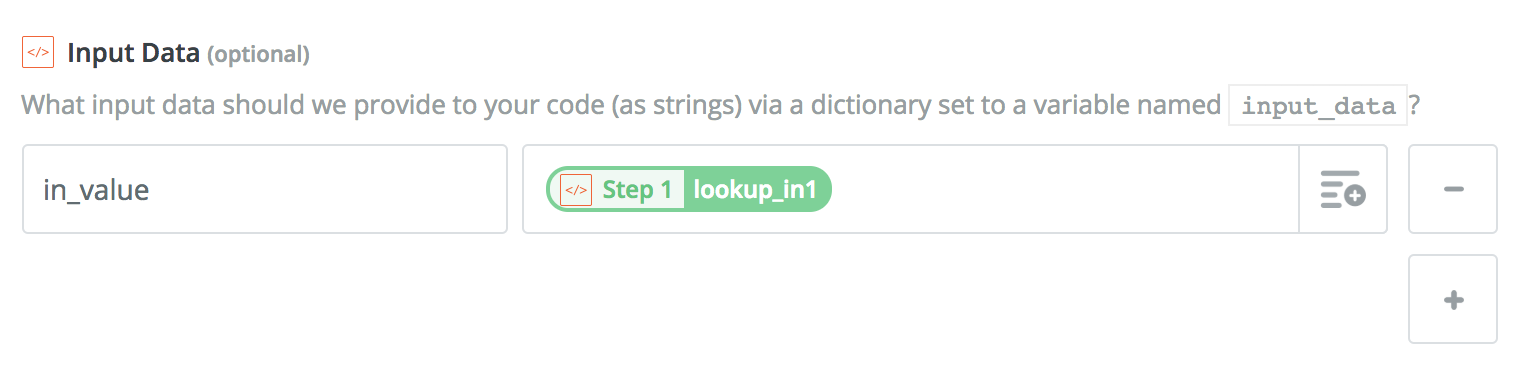
Bulk lookup table
If you have hundreds of values for lookup, you might want to use code instead of the built-in lookup table tool. This makes it easier to manage, but you'll want to set up the input values like this:
output = {'id': 1234, 'hello': 'world!', 'name': input_data['name']}
0
Now you can use the "Out Value" in later steps.